事件循环
重要提示
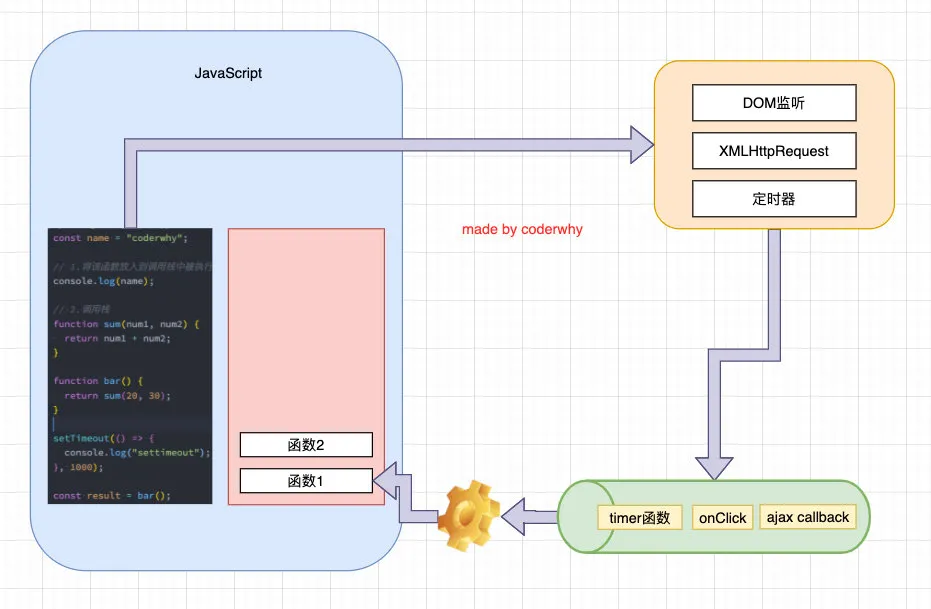
事件循环是什么?事实上我把事件循环理解成我们编写的 JavaScript 和浏览器或者 Node 之间的一个桥梁。
浏览器的事件循环是一个我们编写的 JavaScript 代码和浏览器 API 调用(setTimeout/AJAX/监听事件等)的一个桥梁, 桥梁之间他们通过回调函数进行沟通。
Node 的事件循环是一个我们编写的 JavaScript 代码和系统调用(file system、network 等)之间的一个桥梁, 桥梁之间他们通过回调函数进行沟通的.
浏览器事件循环
js
const name = 'hjf'
// 1.将该函数放入到调用栈中被执行
console.log(name)
// 2.调用栈
function sum(num1, num2) {
return num1 + num2
}
function bar() {
return sum(20, 30)
}
setTimeout(() => {
console.log('settimeout')
}, 1000)
const result = bar()
console.log(result)那么,传入的一个函数(比如我们称之为 timer 函数),会在什么时候被执行呢?
- 事实上,setTimeout 是调用了 web api,在合适的时机,会将 timer 函数加入到一个事件队列中;
- 事件队列中的函数,会被放入到调用栈中,在调用栈中被执行;
宏任务和微任务
但是事件循环中并非只维护着一个队列,事实上是有两个队列:
- 宏任务队列(macrotask queue):ajax、setTimeout、setInterval、DOM 监听、UI Rendering 等
- 微任务队列(microtask queue):Promise 的 then 回调、 Mutation Observer API、queueMicrotask()等
那么事件循环对于两个队列的优先级是怎么样的呢?
- main script 中的代码优先执行(编写的顶层 script 代码);
- 在执行任何一个宏任务之前(不是队列,是一个宏任务),都会先查看微任务队列中是否有任务需要执行
- 也就是宏任务执行之前,必须保证微任务队列是空的;
- 如果不为空,那么就优先执行微任务队列中的任务(回调);
js
setTimeout(function () {
console.log('set1')
new Promise(function (resolve) {
resolve()
}).then(function () {
new Promise(function (resolve) {
resolve()
}).then(function () {
console.log('then4')
})
console.log('then2')
})
})
new Promise(function (resolve) {
console.log('pr1')
resolve()
}).then(function () {
console.log('then1')
})
setTimeout(function () {
console.log('set2')
})
console.log(2)
queueMicrotask(() => {
console.log('queueMicrotask1')
})
new Promise(function (resolve) {
resolve()
}).then(function () {
console.log('then3')
})结果输出:
sh
pr1
2
then1
queueMicrotask1
then3
set1
then2
then4
set2Node 的事件循环
阻塞 IO 和非阻塞 IO
如果我们希望在程序中对一个文件进行操作,那么我们就需要打开这个文件:通过文件描述符。
- 我们思考:JavaScript 可以直接对一个文件进行操作吗?
- 看起来是可以的,但是事实上我们任何程序中的文件操作都是需要进行系统调用(操作系统封装了文件系统);
- 事实上对文件的操作,是一个操作系统的 IO 操作(输入、输出);
操作系统为我们提供了阻塞式调用和非阻塞式调用:
- 阻塞式调用: 调用结果返回之前,当前线程处于阻塞态(阻塞态 CPU 是不会分配时间片的),调用线程只有在得到调用结果之后才会继续执行。
- 非阻塞式调用: 调用执行之后,当前线程不会停止执行,只需要过一段时间来检查一下有没有结果返回即可。
所以我们开发中的很多耗时操作,都可以基于这样的 非阻塞式调用:
- 比如网络请求本身使用了 Socket 通信,而 Socket 本身提供了 select 模型,可以进行
非阻塞方式的工作; - 比如文件读写的 IO 操作,我们可以使用操作系统提供的
基于事件的回调机制;
但是非阻塞 IO 也会存在一定的问题:我们并没有获取到需要读取(我们以读取为例)的结果
- 那么就意味着为了可以知道是否读取到了完整的数据,我们需要频繁的去确定读取到的数据是否是完整的;
- 这个过程我们称之为轮询操作;
那么这个轮询的工作由谁来完成呢?
- 如果我们的主线程频繁的去进行轮询的工作,那么必然会大大降低性能;
- 并且开发中我们可能不只是一个文件的读写,可能是多个文件;
- 而且可能是多个功能:网络的 IO、数据库的 IO、子进程调用;
libuv 提供了一个线程池(Thread Pool):
- 线程池会负责所有相关的操作,并且会通过轮询等方式等待结果;
- 当获取到结果时,就可以将对应的回调放到事件循环(某一个事件队列)中;
- 事件循环就可以负责接管后续的回调工作,告知 JavaScript 应用程序执行对应的回调函数;
阻塞和非阻塞,同步和异步有什么区别?
- 阻塞和非阻塞是对于被调用者来说的;
- 在我们这里就是系统调用,操作系统为我们提供了阻塞调用和非阻塞调用;
- 同步和异步是对于调用者来说的;
- 在我们这里就是自己的程序;
- 如果我们在发起调用之后,不会进行其他任何的操作,只是等待结果,这个过程就称之为同步调用;
- 如果我们再发起调用之后,并不会等待结果,继续完成其他的工作,等到有回调时再去执行,这个过程就是异步调用;